This is a web exploitation challenge from 2021. It’s pretty old but has less solves as of writing this post. I figured, it’s worth talking about.
We are told to visit http://mercury.picoctf.net:60022/index.html where we find a simple textbox prompting us to submit the flag.
Looking at the page source by pressing ctrl u, we see that it is sourcing javascript code from rTEuOmSfG3.js.
<script src="rTEuOmSfG3.js"></script>
While examining the javascript, we will notice that it is obfuscated and packed. Put this through de4js to prettify it.
const _0x143f = ['exports', '270328ewawLo', 'instantiate', '1OsuamQ', 'Incorrect!', 'length', 'copy_char', 'value', '1512517ESezaM', 'innerHTML', 'check_flag', 'result', '1383842SQRPPf', '924408cukzgO', 'getElementById', '418508cLDohp', 'input', 'Correct!', '573XsMMHp', 'arrayBuffer', '183RUQBDE', '38934oMACea'];
const _0x187e = function (_0x3075b9, _0x2ac888) {
_0x3075b9 = _0x3075b9 - 0x11d;
let _0x143f7d = _0x143f[_0x3075b9];
return _0x143f7d;
};
(function (_0x3379df, _0x252604) {
const _0x1e2b12 = _0x187e;
while (!![]) {
try {
const _0x5e2d0a = -parseInt(_0x1e2b12(0x122)) + -parseInt(_0x1e2b12(0x12f)) + -parseInt(_0x1e2b12(0x126)) * -parseInt(_0x1e2b12(0x12b)) + -parseInt(_0x1e2b12(0x132)) + parseInt(_0x1e2b12(0x124)) + -parseInt(_0x1e2b12(0x121)) * -parseInt(_0x1e2b12(0x11f)) + parseInt(_0x1e2b12(0x130));
if (_0x5e2d0a === _0x252604) break;
else _0x3379df['push'](_0x3379df['shift']());
} catch (_0x289152) {
_0x3379df['push'](_0x3379df['shift']());
}
}
}(_0x143f, 0xed04c));
let exports;
(async () => {
const _0x484ae0 = _0x187e;
let _0x487b31 = await fetch('./qCCYI0ajpD'),
_0x5eebfd = await WebAssembly[_0x484ae0(0x125)](await _0x487b31[_0x484ae0(0x120)]()),
_0x30f3ed = _0x5eebfd['instance'];
exports = _0x30f3ed[_0x484ae0(0x123)];
})();
function onButtonPress() {
const _0x271e58 = _0x187e;
let _0x441124 = document[_0x271e58(0x131)](_0x271e58(0x11d))[_0x271e58(0x12a)];
for (let _0x34c54a = 0x0; _0x34c54a < _0x441124[_0x271e58(0x128)]; _0x34c54a++) {
exports[_0x271e58(0x129)](_0x441124['charCodeAt'](_0x34c54a), _0x34c54a);
}
exports[_0x271e58(0x129)](0x0, _0x441124[_0x271e58(0x128)]), exports[_0x271e58(0x12d)]() == 0x1 ? document[_0x271e58(0x131)](_0x271e58(0x12e))[_0x271e58(0x12c)] = _0x271e58(0x11e) : document[_0x271e58(0x131)](_0x271e58(0x12e))['innerHTML'] = _0x271e58(0x127);
}
We will save this to a file called code.js.
The first part is mutating, more specifically rotating, the definitions in
_0x143f until the sum of the integers sprinkled throughout the list equals
0xed04c. Take another look at the code to make sure you can verify why that
is the case.
const _0x143f = ['exports', '270328ewawLo', 'instantiate', '1OsuamQ', 'Incorrect!', 'length', 'copy_char', 'value', '1512517ESezaM', 'innerHTML', 'check_flag', 'result', '1383842SQRPPf', '924408cukzgO', 'getElementById', '418508cLDohp', 'input', 'Correct!', '573XsMMHp', 'arrayBuffer', '183RUQBDE', '38934oMACea'];
const _0x187e = function (_0x3075b9, _0x2ac888) {
_0x3075b9 = _0x3075b9 - 0x11d;
let _0x143f7d = _0x143f[_0x3075b9];
return _0x143f7d;
};
(function (_0x3379df, _0x252604) {
const _0x1e2b12 = _0x187e;
while (!![]) {
try {
const _0x5e2d0a = -parseInt(_0x1e2b12(0x122)) + -parseInt(_0x1e2b12(0x12f)) + -parseInt(_0x1e2b12(0x126)) * -parseInt(_0x1e2b12(0x12b)) + -parseInt(_0x1e2b12(0x132)) + parseInt(_0x1e2b12(0x124)) + -parseInt(_0x1e2b12(0x121)) * -parseInt(_0x1e2b12(0x11f)) + parseInt(_0x1e2b12(0x130));
if (_0x5e2d0a === _0x252604) break;
else _0x3379df['push'](_0x3379df['shift']());
} catch (_0x289152) {
_0x3379df['push'](_0x3379df['shift']());
}
}
}(_0x143f, 0xed04c));
We can paste this into a node interactive REPL and get the final value of _0x143f.
> _0x143f
[
'input', 'Correct!',
'573XsMMHp', 'arrayBuffer',
'183RUQBDE', '38934oMACea',
'exports', '270328ewawLo',
'instantiate', '1OsuamQ',
'Incorrect!', 'length',
'copy_char', 'value',
'1512517ESezaM', 'innerHTML',
'check_flag', 'result',
'1383842SQRPPf', '924408cukzgO',
'getElementById', '418508cLDohp'
]
Notice the function _0x187e used indirectly to access elements of the
list. It is shadowed as _0x271e58 and _0x484ae0 to aid the obfuscation.
Other than that, the function is never called anywhere else. It makes sense
to evaluate the expressions from the function calls and then remove it.
Let’s write a quick python script to do so.
import re
import subprocess
ex = re.compile(r"_0x(271e58|484ae0)\((0x[123456789abcdef0]+)\)")
# Define the list and the indexing function
definitions = """
const _0x143f = [
'input', 'Correct!',
'573XsMMHp', 'arrayBuffer',
'183RUQBDE', '38934oMACea',
'exports', '270328ewawLo',
'instantiate', '1OsuamQ',
'Incorrect!', 'length',
'copy_char', 'value',
'1512517ESezaM', 'innerHTML',
'check_flag', 'result',
'1383842SQRPPf', '924408cukzgO',
'getElementById', '418508cLDohp'
];
const _0x187e = function (_0x3075b9, _0x2ac888) {
_0x3075b9 = _0x3075b9 - 0x11d;
let _0x143f7d = _0x143f[_0x3075b9];
return _0x143f7d;
};
"""
with open('code.js') as h:
contents = h.read()
calls = []
log_calls = []
for fn, call in ex.findall(contents):
shadow_call = "_0x{}({})".format(fn, call)
calls.append(shadow_call)
log_calls.append("console.log(_0x187e({}))".format(call))
with open('code_1.js', 'w') as h:
h.write(definitions)
h.write('\n'.join(log_calls))
evaluated = subprocess.check_output("node code_1.js", shell=True).decode().splitlines()
for call, expr in zip(calls, evaluated):
contents = contents.replace(call, '"{}"'.format(expr))
# Ignore anything we have already evaluated,
# in this case, anything before defining exports.
contents = contents[contents.index("let exports"):]
with open("code_1.js", 'w') as h:
h.write(contents)
We run the above code to get code_1.js.
let exports;
(async () => {
const _0x484ae0 = _0x187e;
let _0x487b31 = await fetch('./qCCYI0ajpD'),
_0x5eebfd = await WebAssembly["instantiate"](await _0x487b31["arrayBuffer"]()),
_0x30f3ed = _0x5eebfd['instance'];
exports = _0x30f3ed["exports"];
})();
function onButtonPress() {
const _0x271e58 = _0x187e;
let _0x441124 = document["getElementById"]("input")["value"];
for (let _0x34c54a = 0x0; _0x34c54a < _0x441124["length"]; _0x34c54a++) {
exports["copy_char"](_0x441124['charCodeAt'](_0x34c54a), _0x34c54a);
}
exports["copy_char"](0x0, _0x441124["length"]), exports["check_flag"]() ==
0x1 ? document["getElementById"]("result")["innerHTML"] = "Correct!" :
document["getElementById"]("result")['innerHTML'] = "Incorrect!";
}
We can interchange the object notations for function calls and array lengths. After renaming some of the variables so that they make more sense, we end up with the following:
let exports;
(async () => {
let blob = await fetch('./qCCYI0ajpD'),
assembly = await WebAssembly.instantiate(await blob.arrayBuffer()),
instance = assembly['instance'];
exports = instance["exports"];
})();
function onButtonPress() {
let value = document.getElementById("input").value;
for (let i = 0; i < value.length; i++) {
exports.copy_char(value.charCodeAt(i), i);
}
exports.copy_char(0, value.length), exports.check_flag() == 1 ?
document.getElementById("result").innerHTML = "Correct!" :
document.getElementById("result").innerHTML = "Incorrect!";
}
The real magic happens when the script downloads a WebAssembly blob and uses the functions exported in it to verify the input. Let’s download the WebAssembly file from the endpoint and decompile it.
wget http://mercury.picoctf.net:60022/qCCYI0ajpD -O blob.wasm
wasm-decompile blob.wasm -o decompiled.wat
Among the functions defined, the copy_char function sticks out as it
appears to perform an xor with a key.
function copy(a:int, b:int) {
var c:int = g_a;
var d:int = 16;
var e:int_ptr = c - d;
e[3] = a;
e[2] = b;
var f:int = e[3];
if (eqz(f)) goto B_a;
var g:int = 4;
var h:int = e[2];
var i:int = 5;
var j:int = h % i;
var k:ubyte_ptr = g - j;
var l:int = k[1067];
var m:int = 24;
var n:int = l << m;
var o:int = n >> m;
var p:int = e[3];
var q:int = p ^ o;
e[3] = q;
label B_a:
var r:int = e[3];
var s:byte_ptr = e[2];
s[1072] = r;
}
Looking through each line, we can simplify this quite a bit.
Here are some ways we can make educated guesses. From the code we see that l
is an integer.
var m:int = 24;
var n:int = l << m;
var o:int = n >> m;
Subsequent left and right shifts by 24 means getting rid of the first 24 / 8 = 3 bytes. Here’s an animation to visualize the process.
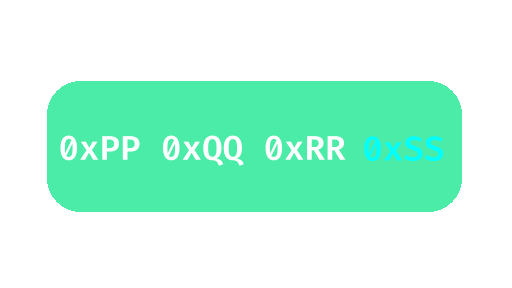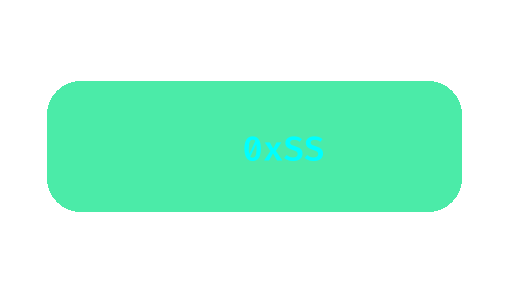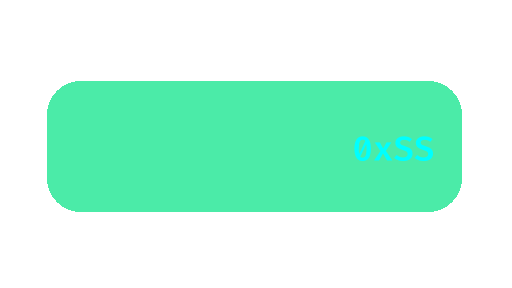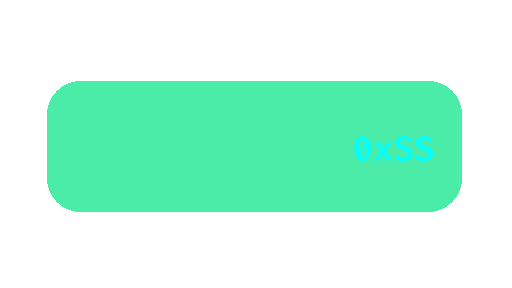
This means l is actually used to index a byte and not an int.
Note: The following code is not
wasm, it’s more akin to pseudocode.
function copy(a:int, b:int) {
var e:int_ptr = g_a - 16;
e[3] = a;
e[2] = b;
// if (eqz(e[3]:int)) goto B_a;
if (*e[3] == 0) {
// b[1072] = e[3];
b[1072] = 0;
}
var k:ubyte_ptr = 4 - (e[2] % 5);
// var l:int = k[1067];
// e[3] = e[3] ^ (l << 24) >> 24;
var l:byte = *(k + 1067);
e[3] = e[3] ^ l;
}
From the beginning of the file, we can infer that some encoded string is
present at offset 1024. Another shorter string starts from offset 1067.
data d_nAa1bd7(offset: 1024) =
"\9dn\93\c8\b2\b9A\8b\c5\c6\dda\93\c3\c2\da?\c7\93\c1\8b1\95\93\93\8eb\c8"
"\94\c9\d5d\c0\96\c4\d97\93\93\c2\90\00\00";
data d_b(offset: 1067) = "\f1\a7\f0\07\ed";
The following confirms that k indexes into the string at offset 1067.
var l:int = k[1067];
Since l is used as the xor byte, the string at index 1067 must be the key.
The variable k rotates from 0 to 4 according to the index of the
character to decide the byte to xor with. xor is an involuntary function,
i.e., if something is xor’d with a key twice, we get the original data back.
Therefore, we can undo the encoding.
We will create a Rust program to do this.
cargo new picoctf
cargo add hex
Add the following code to src/main.rs.
use hex;
use std::error::Error;
fn main() -> Result<(), Box<dyn Error>> {
let key = hex::decode("f1a7f007ed")?;
let crib: Vec<u8> = hex::decode(
// "\9dn\93\c8\b2\b9A\8b\c5\c6\dda\93\c3\c2\da?\c7\93\c1\8b1\95\93\93\8eb\c8"
"9d6e93c8b2b9418bc5c6dd6193c3c2da3fc793c18b319593938e62c894c9d564c096c4d9379393c2900000",
)?
.into_iter()
.enumerate()
.map(|(i, x)| {
let i = 4 - (i % 5);
let x = x ^ key[i];
if x > 0 && x < 0x7f {
x
} else {
0
}
})
.collect();
let result = String::from_utf8(crib)?;
println!("{result}");
Ok(())
}
Now we run the program.
cargo run
picoCTF{b70fcd378740f6e4bce8388c01540c43}
There we have our flag!